What to Expect in CFA Level 1 Quantitative Methods?
CFA Level 1 Quantitative Methods curriculum covers understanding and interpreting a normal distribution and how it relates to quantifying risk. At 6-9% of the exam, Quantitative Methods is given less weight than Ethics and Financial Statement analysis but is weighted more heavily than most topics. Candidates will also become familiar with data visualization, probability distributions, sampling and estimation, hypothesis testing, and regression analysis.
Exam Weighting
The CFA Quantitative Methods topic weighs 6-9%, meaning that approximately 11-16 of the 180 CFA Level 1 exam questions focus on this topic.
| Topic Weight | No. of Learning Modules | No. of Formulas | No. of Questions |
|---|---|---|---|
| 6-9% | 11 | ca. 100 | ca. 16 |
Level 1 Quantitative Methods 2024 Syllabus, Readings, and Changes
While the 2023 CFA Level 1 Quantitative Methods curriculum emphasizes understanding normal distribution, risk quantification, and various topics like data visualization and regression, the 2024 syllabus introduces new topics like Rates and Returns and Big Data Techniques, reflecting contemporary advancements in financial technology. Despite these updates, the core focus on quantitative analysis remains intact.
Rates and Returns
This topic centers on interpreting interest rates as required rates of return, discount rates, or opportunity costs. It emphasizes calculating and interpreting different return measurement approaches, comparing money-weighted and time-weighted rates of return, and evaluating portfolio performance. Additionally, candidates learn to calculate and interpret annualized return measures, continuously compounded returns, and major return measures with a focus on their appropriate applications.
Time Value of Money
We can express one of the core concepts of the time value of money through an age-old proverb—a bird in the hand is worth two in the bush. How does this relate to finance? Money now is worth more than money later: time imposes risk, which has a cost that detracts from value. Therefore, financial analysts must understand how to factor time into valuation.
This reading covers how to calculate
- the future value of a cash flow or a series of cash flows or
- the present value of a cash flow or series of cash flows happening in the future
Candidates are introduced to terminology and concepts that will curate a sense of economic intuition for material covered in later readings.
Statistical Measures of Asset Returns
This topic delves into the intricate world of financial analysis, where we engage in the calculation, interpretation, and assessment of central tendency and location measures. These crucial statistical tools serve as our compass when navigating the complex landscape of investment problems.
In addition to these fundamental concepts, we venture into dispersion measures, striving to comprehend their significance in the context of investment challenges. Furthermore, our exploration expands to encompass the nuanced understanding and evaluation of skewness and kurtosis, offering us valuable insights into the shape and distribution of investment data.
Lastly, we aim to unlock the potential of interpreting the correlation between two variables. This vital skill empowers us to make informed decisions within the framework of addressing intricate investment issues.
Probability Trees and Conditional Expectations
Involves calculating expected values, variances, and standard deviations, showcasing their application to investment problems. Candidates will also learn to formulate an investment problem as a probability tree and understand the application of conditional expectations in investment contexts. Furthermore, the focus extends to calculating and interpreting updated probabilities in investment settings using Bayes’ formula.

Portfolio Mathematics and Simulation Methods
Prospective candidates are required to demonstrate proficiency in several essential quantitative finance skills. These include the ability to calculate and interpret expected values, variances, standard deviations, covariances, and correlations of portfolio returns. Additionally, candidates are expected to possess a comprehensive understanding of risk management, encompassing the definition and evaluation of shortfall risk, the calculation of the safety-first ratio, and the identification of an optimal portfolio through the application of Roy’s safety-first criterion.
Within the realm of Simulation Methods, candidates will acquire the knowledge and expertise necessary to elucidate the normal-lognormal relationship and its significance in modeling asset prices. Furthermore, they will gain proficiency in articulating the principles behind Monte Carlo simulation and mastering the utilization of bootstrap resampling in the context of investment applications.
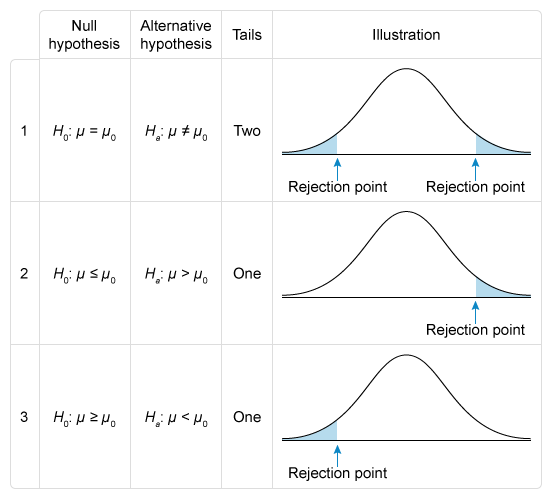
Hypothesis Testing
Analysts sift through an avalanche of data to assess the investment environment and develop hypotheses. To test these hypotheses, analysts will employ statistical inference, allowing them to make judgments about populations based on smaller sample sizes.
- The reading discusses the three quantities commonly used in investments (mean, variance, and correlation) via a hypothesis-testing framework.
Simple Linear Regression
The process of determining relationships between variables is an important tool in the analyst’s toolkit. One of these tools is regression analysis.
- The reading explains the assumptions underlying the simple linear regression model and the roles of independent variables within that model.
- Candidates will also learn to formulate various hypotheses using this tool.
Parametric and Non-Parametric Tests of Independence
This section explains parametric and nonparametric tests concerning the hypothesis that the population correlation coefficient equals zero. Candidates will determine whether the hypothesis is rejected at a specified level of significance. Furthermore, the topic includes explaining tests of independence based on contingency table data.
Introduction to Big Data Techniques
Introduced this year in this topic, the segment covers describing aspects of “fintech” relevant for gathering and analyzing financial data. Candidates will delve into descriptions of Big Data, artificial intelligence, and machine learning. Additionally, the focus extends to describing applications of Big Data and Data Science in the context of investment management.
CFA Quantitative Methods Level 1 Sample Questions and Answers
The sample questions are typical of the probing multiple-choice questions on the L1 exam. During the exam, you have about 90 seconds to read and answer each question, carefully designed to test knowledge from the CFA Curriculum. UWorld’s question bank is built to expose you to exam-like questions and illustrate and explain the concepts tested thoroughly.

What to Expect in CFA Level 2 Quantitative Methods?
CFA Level 2 Quantitative Methods builds on the material covered in Level 1 while emphasizing hypothesis testing. At 5-10% of the exam, Quantitative Methods is one of the less heavily weighted topics. Candidates will become familiar with tools used to identify relationships among variables and examine fintech, machine learning, and sentiment analysis related to developing an investment hypothesis.
Exam Weighting
The CFA Quantitative Methods topic has a weight of 5-10% of the total exam content, so approximately 4-8 of the 88 CFA Level 2 exam questions, or 1-2 of the 22 item sets focus on this topic.
| Topic Weight | No. of Learning modules |
No. of Formulas |
No. of Questions |
|---|---|---|---|
| 5-10% | 7 | ca. 50 | ca. 4-8 |
Level 2 Quantitative Methods 2024 Syllabus, Readings, and Changes
In 2024, the CFA Level 2 Quantitative Methods syllabus covers 7 learning modules, constituting approximately 14.3% of the total curriculum. Notably, several readings have either been consolidated into a single reading or diversified into two or more distinct readings for enhanced comprehension and coverage.
Basics of Multiple Regression and Underlying Assumptions
Financial analysts typically work with sophisticated statistical models that involve more than one independent variable. For example, analysts may want to assess particular macroeconomic variables behind the demand for an individual company’s products or services. To make such assessments, analysts employ multiple linear regression (linear regression with more than one independent variable) to make such assessments.
- The reading introduces the core principles and models of multiple regression models and the foundational assumptions applied to and adjusted for real-world situations.
- Candidates will learn to diagnose an assumption violation and to adjust to these violations.
- The reading also dives into the role of logistic regression in machine learning for Big Data analysis.
Evaluating Regression Model Fit and Interpreting Results
The reading helps understand:
- How well a multiple regression model explains the dependent variable by analyzing ANOVA table results and measures of goodness of fit
- The hypotheses on the significance of two or more coefficients in a multiple regression model and interpret the results of the joint hypothesis tests
- The Calculation and interpretation of a predicted value for the dependent variable, given the estimated regression model and assumed values for the independent variable
Model Misspecification
The reading helps understanding:
- How model misspecification affects the results of a regression analysis and how to avoid common forms of misspecification
- The types of heteroskedasticity and how it affects statistical inference
- Serial correlation and how it affects statistical inference
- Multicollinearity and how it affects regression analysis

Extensions of Multiple Regression
Financial analysts commonly utilize advanced statistical models that incorporate multiple independent variables. One such application involves evaluating specific macroeconomic factors that influence the demand for a company’s products or services. To perform these assessments effectively, analysts rely on the technique known as multiple linear regression, which enables the analysis of relationships between multiple independent variables and a dependent variable. This comprehensive approach is explored through four dedicated learning modules, each delving into the intricate aspects of multiple regression analysis, including:
- The core principles and models of multiple regression models and the foundational assumptions applied to and adjusted for real-world situations.
- The diagnosis of an assumption violation and relevant adjustments.
- The role of logistic regression in machine learning for Big Data analysis.
Time-Series Analysis
A set of these progressive observations is known as a time series, for example, a company’s quarterly sales over three years.
- The reading explores the two fundamental uses of time-series models: understanding the past and forecasting the future of a time series.
- Candidates will learn to estimate time-series models and how these models explain the changes in a time series over time.
Machine Learning
Since their introduction in the 1990s, machine learning techniques have become an integral tool in the toolkits of investment firms. Machine learning (ML) aids analysts in discovering new sources of value and efficiently executing trades.
- The reading provides an overview of machine learning and essential machine learning algorithms applied to investing.
- Candidates will learn about unsupervised machine learning algorithms, neural networks, deep learning nets, and how to choose an appropriate ML algorithm for the task.
Big Data Projects
Big data is an umbrella term that refers to data generated by organizations (businesses, financial markets, governments), individuals (credit cards, social media), sensors, and the Internet of Things. The true impact of big data on financial analysis is yet to be fully understood, but it has already become an integral part of analysts’ toolkits. Data can aid analysts in developing their hypotheses, and forecasting trends in asset prices, detecting anomalies, etc.
- Candidates will learn about the concepts that allow analysts to make predictions using structured and unstructured data.
- The reading provides a real-world ‘big data’ project case study that uses sentiment analysis to assess stock movements.
CFA Quantitative Methods Level 2 Sample Questions and Answers
The sample questions here are typical of the L2 exam’s complexity and depth: formatted as item sets, with a vignette to deliver a scenario that tests the CFA L2 Curriculum. (On the actual exam, each vignette applies to four questions; we’ve thrown in a couple extra to learn more). And be sure to review the illustrated explanations we’ve provided for each question: UWorld’s question bank is designed to expose you to exam-like questions and explain the concepts tested thoroughly.
Passage
Jae Park, CFA, is a manager of a hedge fund that bases its security selection on advanced quantitative analysis. For several open job positions with the fund, Park is looking to hire people with scientific and research backgrounds. Using multiple regression, she would like to evaluate the relationship between the expected salary of the candidates based on their years of experience (EXP), number of published research papers (PRP), and amount of grant funding received in their career (GF). The results of that regression are shown below, along with sample critical values. Park wishes to test the results at a 5% significance level (α = 0.05).
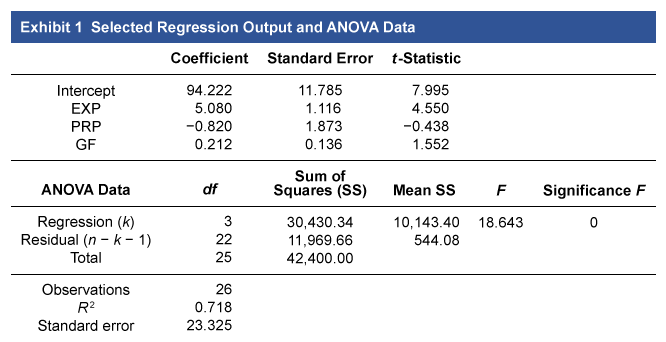
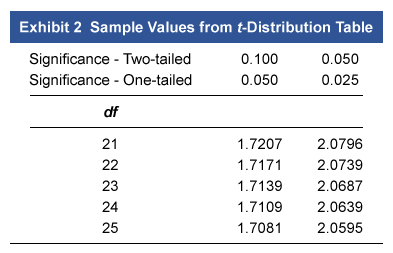
Park also notices that each candidate attended one of five universities. She is considering how to add a variable for university attended to the regression model and believes dummy variables are the best way to capture this.
Finally, Park suspects that her regression in its current form may violate regression assumptions. Her concern is that her model might have an artificially large R2 and t-statistics that are understated.

{kind=link}
{kind=link}
What to Expect in CFA Level 3 Quantitative Methods?
The CFA Institute does not provide a stand-alone Level 3 Quantitative Methods curriculum. However, the foundational knowledge in the Level 1 and Level 2 curriculum is implicit at CFA Level 3.
